
SPARC Data Submission Overview
Steps to submit a dataset, get the data curated, release the data under embargo, and eventually make the data publicly available on the SPARC Portal
Not funded by SPARC but want to submit data?
- Get started by sending an email to [email protected]
General Overview

SPARC is now an open repository, accepting datasets on PNS and its interactions with the CNS and end organs. We are in the process of updating our documentation and platform to make it easier for non-SPARC investigators to utilize the platform. Contact [email protected] for more information about using SPARC for your project.
This documentation only applies to investigators funded through the NIH SPARC effort. It details the steps investigators need to take to submit a dataset to the SPARC Portal.
-
Dataset submission is required within 30 days of completing a project milestone (according to the SPARC Material Sharing Policy).
-
SPARC datasets are required to be published within one year of the milestone completion date listed in the respective deliverable documents of the project.
Disclaimer: this workflow is current as of March 2022 and may be changed over the course of the SPARC project.
Submission Timeline

Contributors are directly involved in the steps indicated in purple.
To Get Started
- Read more about the SPARC requirements for organizing and sharing all SPARC datasets.
- Contact the curation team to discuss the type of data and specific data formatting requirements
- Zoom Office Hours - Tuesdays at 9 a.m. and Thursdays at 1 p.m. US Pacific Time (details here).
- Email [email protected].
- Each investigator has user credentials for the SPARC Consortium group on the Pennsieve website. All SPARC-related datasets should be submitted to this account, even though the investigator might have a separate, unaffiliated, private Pennsieve account.
- Fill out the Pennsieve/Slack Account Request form to obtain access to the SPARC Consortium organization (contact [email protected] for help).
- Download the SODA data submission tool fairdataihub.org/sodaforsparc.
- Tip: Using the SODA tool _greatly simplifies and automates the data upload process.
- Download and install the Pennsieve agent required to upload files through SODA.
- Request access to the SPARC workspace on protocols.io
Preliminary Steps
A SPARC dataset is comprised of the following data and structure:
- Data files are organized into folders by the investigators and curated according to the SPARC Dataset Structure . Data organization and submission in compliance with SDS is greatly simplified and automated by SODA (Software to Organize Data Automatically).
- An experimental protocol is one that has been submitted to Protocols.io , shared with the SPARC working group , and curated by the curation team
- All data are uploaded to the Pennsieve platform.
Organize Dataset According to the SPARC Dataset Structure
Datasets submitted to the SPARC Portal must follow the official SPARC Data Structure (SDS). Following the SDS formatting fosters consistency and organization throughout the portal. The dataset template 2.0.0 with examples of folder structures can be downloaded as a zip file.

Prepare Metadata and Descriptive Files
SPARC dataset files and folders include sets of metadata contained in a set of spreadsheet templates. These mandatory descriptive files containing the metadata are essential for understanding your dataset. Make sure you are always using the most recent template version.
- Some of the folders and metadata templates have specific file names. The names of these key folders and the templates must be kept the same between different dataset submissions.
- Do not add, edit, or delete required columns/rows or change any column headings in any mandatory descriptive files (templates).
- If you wish to add additional metadata (always encouraged), please append a new column to the right-hand side (Subject and Sample files) to include critical metadata not corresponding to available columns. The dataset_description.xls template should not be changed at all.
- Leave fields empty when there is no information available at the time of submission.
- As described above, the use of SODA greatly simplifies and automates this step
For more information, reference this document about each metadata file.
Organize Data in Folders
Data files are organized into top-level folders, depending on the type of data.
primary: a required dataset dependent folder that contains all folders and files for experimental subjects and/or samples, e.g., time-series data, tabular data, clinical imaging data, genomic, metabolomic, microscopy data. The data generally have been minimally processed so they are in a form ready for analysis. Within the primary folder, data is organized by subjects or samples. All subjects and samples will have a unique folder with a standardized name corresponding to the exact names or IDs as referenced in the subjects and samples metadata file.
source: an optional folder containing unaltered, raw files from an experiment, if they are included in the data. For example, this folder may include the “truly” raw k-space data for a Magnetic Resonance (MR) image that has not yet been reconstructed. In this case, the reconstructed DICOM or NIFTI files would be found within the primary folder.
derivative: a required folder if derivative data exists. This folder contains derived data files. For example, processed image stacks that are annotated via the MicroBrightField (MBF Biosciences) tools, segmentation files, or smoothed overlays of current and voltage that demonstrate a particular effect. If files are converted into a format other than what was submitted, these files are included in the derivative folder. Derived data should be organized into subject and sample folders, using the subject and sample IDs as the folder names, as with the primary data.
code: a required folder only if code is used in the generation of the data; the folder contains all the source codes used in the study such as text and source code (e.g., MATLAB, etc.). Links to supporting code that provides added value to the dataset can be included in the metadata description but does not have to be uploaded here.
protocol: an optional folder that contains supplementary files to accompany the experimental protocols submitted to Protocols.io. Please note that this is not a substitution for the experimental protocol which should have been already submitted to Protocols.io/workspaces/sparc .
docs: an optional folder that contains all the supporting documents for the dataset, including but not limited to, a representative image for the dataset. Unlike the readme file, which is a text document, docs can contain documents in multiple formats, including images.

Example of dataset organized according to SPARC Dataset structure
Follow Naming Convention
A consistent and predictable naming scheme for all files makes the dataset easier for other investigators to understand and for computers to process. For SPARC SDS, it is absolutely critical that the naming used within metadata files is consistent with the naming used for folders (e.g., subject or sample names). Note (see below), you can be flexible with your subject names but you must use that same EXACT name when labeling your folders to easily relate the metadata contained in the descriptive file to the contents of the folder.
File Names
- There is no limit to the character number.
- All file names can include only alpha and numeric characters (0-9, A-Z, a-z), and the dash character (-).
- Special characters and empty spaces are not allowed.
Subject and Sample Identifiers (IDs)
- Must be unique for the dataset.
- Must have prefixes: sub- for subjects, and sam- for samples.
- Can include only alpha and numeric characters (0-9, A-Z, a-z), and the dash character (-).
- Special characters and empty spaces are not allowed.
Folder Names
When naming the dataset’s sub-folders, it is imperative to keep a consistent naming scheme.
Folder names must reflect EXACT subject and sample IDs in the name of the folder.
Sample folders should be placed inside the corresponding subject folders.
Each data file must be listed in the main manifest with an adequate description.
Prepare Manifest Files
Manifest files provide information about specific files contained in a folder. For example, a folder may contain a file named mov_colon_stim.mp4. To make sure that your data are understandable, provide a brief description of the contents of this file along with other key metadata. File-level manifest files are required in all main folders. SODA creates a list of files for a manifest automatically during the upload, so you can easily fill in the associated metadata. Users uploading datasets directly to Pennsieve are required to create this file manually for each submitted top-level folder.
Further details about the structure are provided in this presentation and the project’s white paper.
Prepare and Share Experimental Protocols
- Each dataset should be supplemented with detailed experimental protocols prepared and hosted on Protocols.io.
- Links to the editable associated protocols created on the Protocols.io platform should be included in the dataset_description file.
- Protocols are also subject to the curation process and can be published after review by the Curation Team.
- Refer to the Protocol guidelines and recommendations for SPARC Project.
Upload Dataset to Pennsieve
SPARC Investigators should register with the SPARC Consortium group on Pennsieve. Only registered members of the SPARC group can upload data to the platform. SPARC recommends using SODA to organize and upload data. Alternatively, the upload can be done through Pennsieve Direct Upload. In both upload options, it is essential to maintain consistency across the metadata and folder organization.
What is SODA and Why Should I Use It?
- An open-source desktop computer software
- Available for Windows, macOS, and Linux
- Accessible at fairdataihub.org/sodaforsparc
- Prepares dataset on Pennsieve (banner image, license, subtitle, etc.)
- Helps you prepare metadata files (submission, dataset_description, etc.)
- Guides you through organizing data files according to SDS and uploads them on Pennsieve
- Detailed instructions are available our guide on how to prepare and submit SPARC datasets with SODA.
How Pennsieve Direct Upload Works
- Recommended for advanced users
- Users must strictly adhere to the SDS file structure and standards.
- The help pages and tutorials for the Pennsieve platform are directly available from the Pennsieve documentation.
- Detailed instructions are provided on how to prepare and submit SPARC datasets with Pennsieve Direct Upload.
Tips:
- Be patient: it might take hours to upload large files or large numbers of files.
- Verify that all data files and folders were uploaded correctly to the platform.
- If any errors occur during the upload, make a note or take a screenshot - this will help the SODA and Pennsieve teams troubleshoot. When encountering problems using SODA please email [email protected], when dealing with Pennsieve please use the chat function in the right corner of the page.
Submit Dataset for Publication Review
The dataset owner MUST submit the dataset to initiate the curation process. Only the person listed as the dataset owner can submit it for review.
This step can be completed in the:
- Disseminate Dataset tab of SODA. Submit for pre-publishing review.
- Setting tab of Pennsieve. Request to Publish
When working directly on Pennsieve platform the dataset owner should:
- Log in to the SPARC Consortium account on the Pennsieve platform.
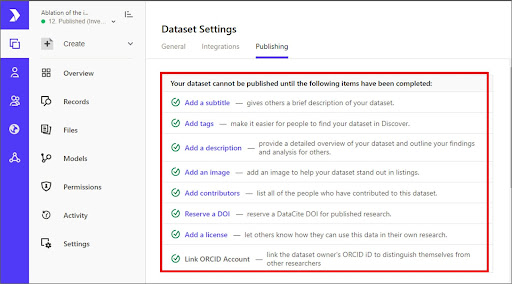
- Click on the dataset title to access the Overview panel and dataset publishing checklist.
- Complete all the items listed in the Dataset Publishing Checklist. Completed items will be marked with a green check.
-
To connect your ORCID iD to Pennsieve please do the following:
-
Hover over your initials in the lower-left corner of the screen and click View My Profile (please note: you can link your ORCID iD only via your profile).
Click Register or Connect Your ORCID iD
-

The new pop-up window will appear. Follow the prompts to grant the Pennsive platform permission to obtain your ORCID iD either by logging in to your ORCID account or by registering to create an ORCID iD.
- Click Settings (at the left side of the screen).

- Select the Publishing tab and scroll down to find the Request to Publish button.
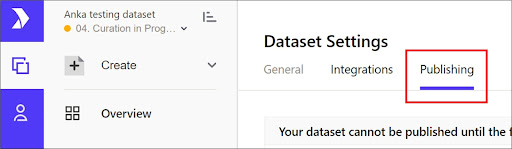
- Click the Request to Publish button - please note that this button will not be active if the ORCID ID of the owner is not linked to Pennsieve.

- In the pop-up window, check the first box and press the Submit button.

The second box is only to be checked if the dataset is eligible for embargoed release (no more than one year from the milestone competition date).
Important: Submitting the dataset for review will initiate the curation process BUT will lock the dataset and will prevent the contributors from editing or adding new files. All edits and or changes, from that point, will have to be facilitated by the curation team.
If your dataset is associated with a manuscript that has been submitted to a journal or is to be submitted soon, please provide manuscript information in the dataset_description file, including the expected publication date. The SPARC Team will do their best to prioritize your dataset so that you can point your readers to your SPARC data.
Please refer to the article Formatting SPARC Datasets for information on how SPARC datasets are organized.
Resource Compendium
SPARC 2.0 dataset structure Google Slides presentation
Dataset template description (currently at version 2.0.0)
SPARC Template Github download
SPARC Data Structure: Rationale and Design of a FAIR Standard for Biomedical Research Data
Updated about 1 year ago