
Navigating SPARC Datasets
Learn SPARC's file structure to simplify browsing and use of SPARC datasets.
General Organization
SPARC Portal hosts a growing collection of diverse datasets spanning anatomy, physiology, modeling, and simulation. A file structure and naming convention, SPARC Data Structure (SDS), was implemented to provide consistency across all datasets. Understanding SDS may prove helpful in browsing and utilizing SPARC data.
For each SPARC dataset, you can:
1. Explore dataset
Clicking the SPARC dataset title will take you to a dataset landing page. This page provides basic information about the dataset, such as title, contributors, size, version, related publications, links to protocols, experimental design, subjects, and whether the dataset is part of a larger study. Clicking the tabs listed next to the Abstract tab allows you to view more details, including the corresponding author, associated projects, and instructions on citing the dataset. The Gallery tab offers a web preview of the microscopy image data along with anatomical scaffolds, flatmaps, segmentation, and videos (if available). You can also browse the dataset files by clicking the Files tab.
2. Download data:
The dataset can be downloaded directly from the landing page or from the Files tab. Click the Get Dataset button to download the entire dataset from the landing page.
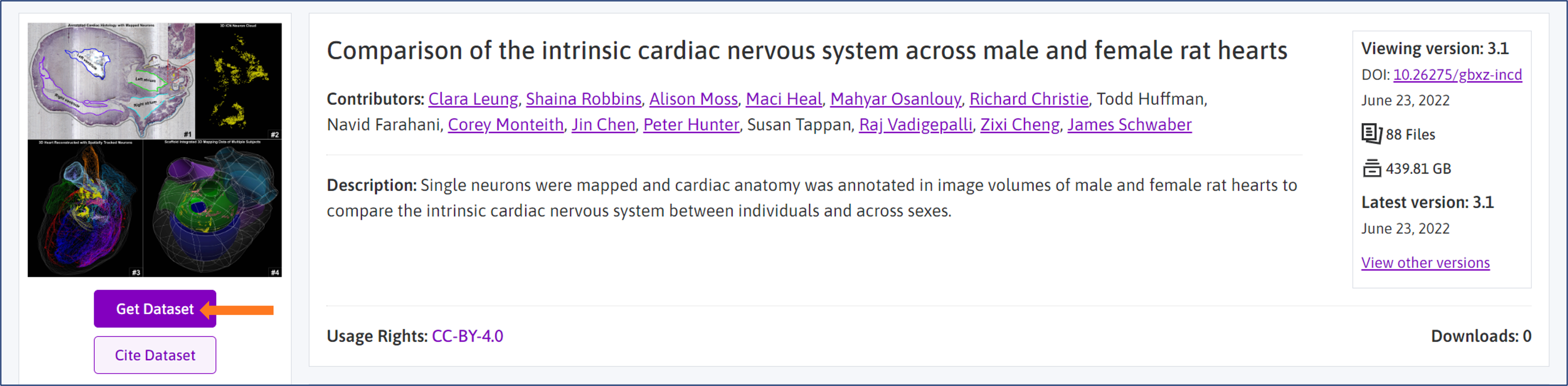
Go to the Files tab on the landing page to download individual folders and files.
Note: Datasets, folders, and individual files below 5 GB can be downloaded free of charge. Datasets, folders, and files above 5 GB require an Amazon S3 account and may incur charges.
To learn how to create a free AWS account and download dataset files with S3, go to:
- Accessing Public Datasets
- Using AWS to Access Public Datasets
- Setting up an AWS Account to Access Large SPARC Datasets
3. Browse data files:
You can also browse available data files and metadata through the portal and download individual data files. To access the data file structure, click on the Files tab.
SPARC Dataset Structure
Clicking the File tab will take you to the dataset folders and files. Dataset folders contain data, code, and supporting materials. These folders are accompanied by documents and spreadsheets containing critical metadata needed to understand the content of the folders.
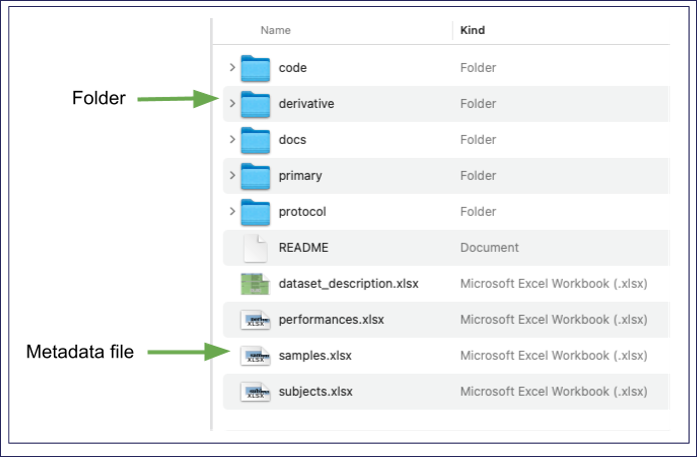
Metadata files:
The following metadata files are available:
- dataset_description: provides general information about the dataset.
- subjects: lists subjects by their identifiers along with key details such as age, weight, and experimental groups.
- samples (if needed): lists specimens used in the study by their identifiers and key details.
- README: provides instructions on using the dataset, descriptions of the file directories, challenges and limitations in obtaining data, information on missing data points or dropped subjects, etc. The README file in the code folder includes information about the code.
File Folders:
Data, code, and additional documents are organized into folders.
Note: Depending on the nature of the dataset, not all datasets have all folders described below.
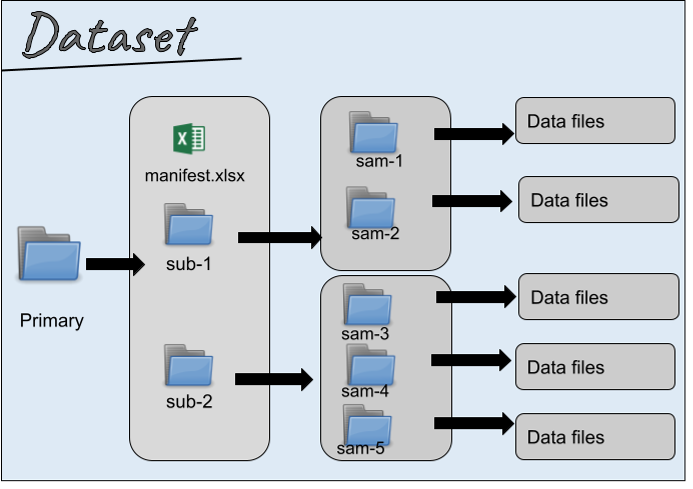
Primary Folder:
The primary folder is required for all experimental datasets and contains the main data products, e.g., images, spreadsheets, physiological traces, etc. You may see more than one type of data in the primary folder.
Note: Primary folder may contain minimally processed data, e.g., a stitched mosaic. In this case, the raw data (i.e., data that comes right off the instrument) may be found in the Source folder (not shown).
Data files in the primary folder are organized by subjects and/or samples. Each subject/sample has its folder named accordingly to the identifiers found in the subject and/or sample files described above. Data derived directly from the subject, e.g., recordings from the brainstem in vivo, are accessible after opening the subject (sub-) folder. Data collected at multiple time points can be found in the performances (perf-) folder and are accompanied by the metadata file “performances.” Data derived from specimens, e.g., microscopy images, are available in the sample (sam-) folders.
Note: Some investigators can further organize the data within the subject and/or sample folder, depending on the type of data.
Derivative folder:
This folder contains products derived from the original data, e.g., measurements from images, 3D reconstructions, or converted files.
Docs folder:
Here, you can find supplementary material necessary to understand the dataset, e.g., figures or diagrams.
Code folder:
If a code is a part of the dataset, you can find it in the code folder. This folder will also contain a README file that provides information on how to install and run the code, what are the inputs, outputs, expected results, and any dependencies.
Manifest file
Each of the top-level folders described above includes a manifest file. This file lists all files within the folder and provides additional information about the files.
4. Working with a SPARC dataset
Understanding the metadata files is critical for understanding the data folders. Currently, browsing individual SPARC dataset files involves manually opening the files. As the SPARC Portal evolves, new functionalities will be implemented.
To browse a dataset in the SPARC Dataset viewer:
The SPARC Dataset viewer is a beta version web-based tool that allows one to quickly visualize SPARC datasets in a graphical viewer. It gives users a visual overview of the folders, files, subjects, samples, and metadata associated with datasets that adhere to the SPARC dataset structure.
To browse a dataset in the SPARC Portal:
-
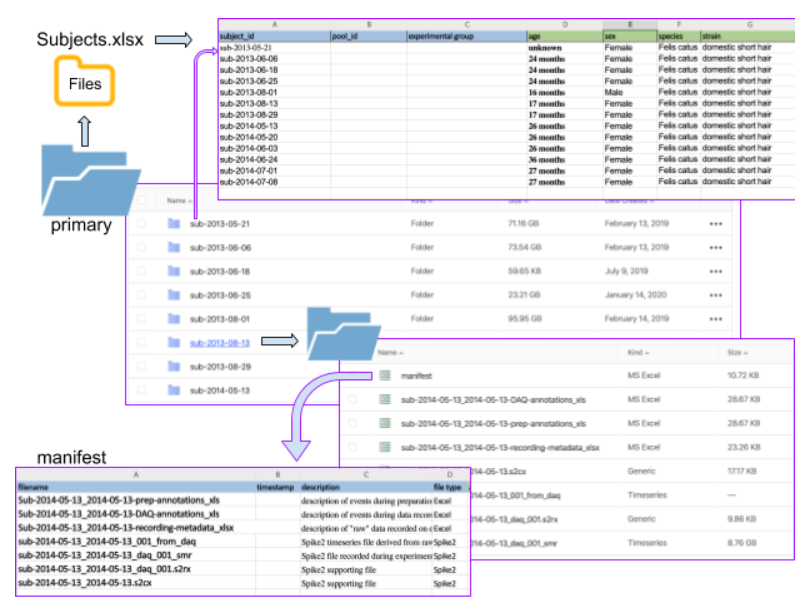
Open the primary data folder in the main directory.
-
Open the subjects.xlsx file from the main directory.
-
The names of the subfolders in the primary folder should match the subject IDs listed in the subject file.
-
Open a folder for an individual subject.
- If data were derived directly from a subject, you will see data files.
Note: when multiple types of data are acquired from the same subject, they may be organized into subfolders.
- If data are derived from specimens, you will see another folder labeled with the sample name (not shown above). Details about the specimen IDs can be found in the samples.xlsx file in the main directory.
-
In the Primary folder, look for a manifest file to find details about the contents of the directory.
Updated 4 months ago